検索結果のURLとタイトルの個数を指定しwebスクレイピングをして、そのlistをつくるプログラムを作成していこうと思う。
プログラムの作成
プログラムの概要
取得する個数を決めて、その分だけlistに入れていく仕様にする。また、ページの移動もするため、ページ移動するプログラムも書いていく
初めの部分
from requests_html import HTMLSession
session = HTMLSession()
#検索に利用するサイト
url = "https://www.google.com/"
#検索するワード
word = "python"
#格納する個数
n = 20
r = session.get(url + "search?q=" + word)
all_list = list()いつも通りimport文などを書いていく。今回は個数を指定するため変数”n”を定義し、その中に数字を入れた。また入れるためのリストも”all_list”としてここで定義しておいた。
listに格納する
#listに格納
def to_list(number):
r.html.render()#HTMLを生成
elements = r.html.find('.yuRUbf')
for element in elements:
url = element.find('a',first=True)
url = url.links #set型
url = list(url) #list化
title = element.find('span',first=True) #タイトル取得
url.insert(0,title.text) #テキスト化してurlのインデックス0番目に挿入
#格納数の判別
if len(all_list) < number: #指定個数を超えないための条件
all_list.append(url)
else:
breaklistに入れるための関数を作った。引数として、格納する個数を指定。
関数の中の1、2行目でURLとタイトルの入っている要素を取り出している。
for文を使い要素を一個ずつ取り出し、URLとタイトルを取り出している。ここで”url”をlist化してそのlistのインデックスが0の位置に”title”を入れている。
if分の条件は個数を超えてlistに格納しないようにしている。超えてしまった場合はbreakで止めている。そしてこのif分の中で”all_list”へ格納する。
次のページに移動
1ページに表示される検索結果は限界があるため次のページに移動する必要がある。
#次のページに飛ぶ
def jump():
global r #global化
next_url = r.html.find('#pnnext') #次のページのURLが書かれている要素をIDで指定
next_url = next_url[0].absolute_links #URLの取得
next_url = list(next_url) #set形で返されるため、list型に変換
r = session.get(next_url[0]) #次のページのURLを読み込む関数をjumpと定義。ここで一つ注意が必要。rはこの関数の外で定義しているがこの関数内で書き換えるためglobal化する必要がある。
関数の中身は次のページへ行くためのurlが書かれている部分を探しそのURLを取得した。
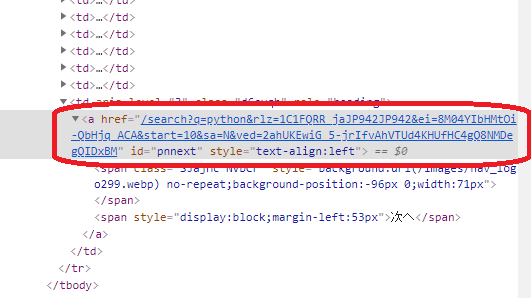
このとき、画像を見てもらえばわかると思うが次のページのURLがhttpから始まっていない。もしlinksを使ってURLを取得するとここに書かれている状態のままなのでこれでは読み込まれない。そのためabsolute_linksを使ってURLをとるように。
最後の分で次のページのURLを読み込んでいる。
これらを繰り返す
while len(all_list) < n:
to_list(n)
jump()これらの関数をwhile文で繰り返せば完成。この時の条件は”to_list”の関数内のif分と同じである。
結果を見てみる
for i in range(len(all_list)):
print(i + 1,end='')
print(all_list[i])しっかりとlistに格納されているか見るために”print”で表示。見やすくするためにfor文を使って一個ずつ取り出していく。また、番号もつけていく
結果はこんな感じになった。
1['プログラミング言語 Python - python.jp', 'https://www.python.jp/']
2['Pythonってどんな言語なの?:Python入門(1/2 ページ) - @IT', 'https://www.atmarkit.co.jp/ait/articles/1904/02/news024.html']
3['Welcome to Python.org', 'https://www.python.org/']
4['Python - Wikipedia - ウィキペディア', 'https://ja.wikipedia.org/wiki/Python']
5['Python | プログラミングの入門なら基礎から学べるProgate ...', 'https://prog-8.com/languages/python']
6['Pythonの開発環境を用意しよう!(Windows ...', 'https://prog-8.com/docs/python-env-win']
7['Pythonってどんな言語? 特徴と歴史を『独習Python』から ...', 'https://codezine.jp/article/detail/12457']
8['Python入門 ~Pythonのインストール方法やPythonを使った ...', 'https://www.javadrive.jp/python/']
9['とほほのPython入門 - とほほのWWW入門', 'http://www.tohoho-web.com/python/']
10['Pythonとは?大人気プログラミング言語のメリットや活用事例 ...', 'https://www.internetacademy.jp/it/programming/programming-basic/what-is-python.html']
11['Python画像処理 - Qiita', 'https://qiita.com/tags/python']
12['Pythonやデータサイエンティスト入門が無料に | Ledge.ai', 'https://ledge.ai/meti-learning-0225/']
13['PyQ(パイキュー) - 本気でプログラミングを学びたい人の ...', 'https://pyq.jp/']
14['Python3入門編のレッスン一覧 | プログラミング学習サービス ...', 'https://paiza.jp/works/python3/primer']
15['Python入門 | 10秒で始めるAIプログラミング学習サービス ...', 'https://aidemy.net/courses/3010']
16['講座情報詳細|機械学習のためのPython入門講座 (METI/経済 ...', 'https://www.meti.go.jp/policy/it_policy/jinzai/sugomori/020.html']
17['初めてのPython 第3版 | Mark Lutz, 夏目 大 |本 | 通販 | Amazon', 'https://www.amazon.co.jp/%E5%88%9D%E3%82%81%E3%81%A6%E3%81%AEPython-%E7%AC%AC3%E7%89%88-Mark-Lutz/dp/4873113938']
18['みんなのPython 第4版 | 柴田 淳 |本 | 通販 | Amazon', 'https://www.amazon.co.jp/%E3%81%BF%E3%82%93%E3%81%AA%E3%81%AEPython-%E7%AC%AC4%E7%89%88-%E6%9F%B4%E7%94%B0-%E6%B7%B3/dp/479738946X']
19['Python | チュートリアル、API、SDK、ドキュメント | AWS ...', 'https://aws.amazon.com/jp/developer/language/python/']
20['Google App Engine での Python | App Engine ドキュメント ...', 'https://cloud.google.com/appengine/docs/python?hl=ja']しっかりと指定した個数分だけlistに格納されているのがわかる。
まとめ
完成したプログラムはこんな感じ
from requests_html import HTMLSession
session = HTMLSession()
#検索に利用するサイト
url = "https://www.google.com/"
#検索するワード
word = "python"
#格納する個数
n = 20
r = session.get(url + "search?q=" + word)
all_list = list()
#listに格納
def to_list(number):
r.html.render() #HTMLを生成
elements = r.html.find('.yuRUbf')
for element in elements:
url = element.find('a',first=True)
url = url.links #set型
url = list(url) #list化
title = element.find('span',first=True) #タイトル取得
url.insert(0,title.text) #テキスト化してurlのインデックス0番目に挿入
#格納数の判別
if len(all_list) < number: #指定個数を超えないための条件
all_list.append(url)
else:
break
#次のページに飛ぶ
def jump():
global r #global化
next_url = r.html.find('#pnnext') #次のページのURLが書かれている要素をIDで指定
next_url = next_url[0].absolute_links #URLの取得
next_url = list(next_url) #set形で返されるため、list型に変換
r = session.get(next_url[0]) #次のページのURLを読み込む
while len(all_list) < n:
to_list(n)
jump()
for i in range(len(all_list)):
print(i + 1,end='')
print(all_list[i])今回は必要な個数分だけ情報をとれるようなプログラムを作った。次のページに行くのが意外と厄介だった。