今回は実際にrequests-htmlを利用してwebスクレイピングするプログラムを作成しようと思う。
requests-htmlに関しては以前書いているのでそちらを参考にしてほしい。
今回はgoogleで検索をおこない、この検索結果のページタイトルとURLをwebスクレイピングで収集するプログラムを作りたいと思う。
では実際にプログラムを作成していこうと思う。
準備するもの
今回はpython,requests-htmlを利用することが前提なのでそこらへんの説明は省略させてもらう。
他に関してはpythonを動かせる環境とネット環境があれば特に必要なものはない。
プログラムの作成
最初にwebスクレイピングする上で必要なプログラムを書いていく
from requests_html import HTMLSession
session = HTMLSession()
#検索に利用するサイト
url = "https://www.google.com/"
#検索するワード
word = "python"
r = session.get(url + "search?q=" + word)
r.html.render()googleで検索を行うためURLにgoogleのページを指定しました。
検索ワードを変えられるようにwordという変数に検索ワードを入れました。
seleniumなどでブラウザを操作して検索する方法もあるが今回はrequests-htmlだけを利用してプログラムを作るため、6行目のような形にし直接検索結果のURLとなるようにしました。
6行目で”r”という変数に検索結果の情報を格納している。
次に”r”にある情報から欲しい情報を探す
検索結果のURLとタイトルの該当箇所のHTMLタグを確認します。ブラウザでgoogleの検索結果のページを開きます。
ページ内の目的の該当箇所で右クリックをし、一番下の検証をクリックします。

すると、右側にデベロッパーツールが現れ、先程選択した部分がHTMLのどこの部分か表示されます。
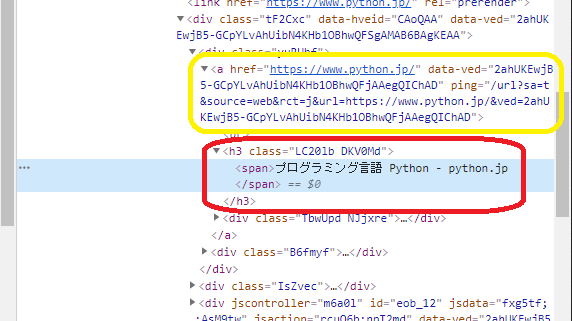
この黄色で囲まれた部分が選択したURLで、赤で囲まれた部分がタイトルの部分である。このことからURLのタグは<a>のherf属性でリンクを示しており、タイトルのタグは<span>であることがわかった。
実際にこの部分の情報を取り出してみたいと思う。
求めている情報の検索
まず始めにタグ<span>を検索しタイトルを表示させたいと思います。
titles = r.html.find('span')
for title in titles:
print(title.text)すると結果は以下のようになりました。
もっと見る
設定
プログラミング言語 Python - python.jp
キャッシュ
類似ページ
//省略//
ヘルプフィードバックを送信プライバシー規約
ヘルプフィードバックを送信プライバシー規約結果を見てみると余計な部分の情報まで拾っています。なのでもう少し限定的に検索をかけることにします。
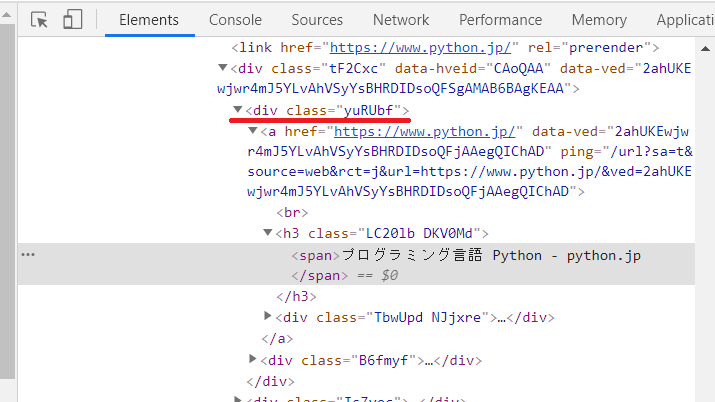
これを見ると、class名が”yuRUbf”の1つ目の<a>と<span>が求めるURLとタイトルということがわかる。これをふまえてプログラムを書いてみる。
elements = r.html.find('.yuRUbf')
for element in elements:
url = element.find('a',first=True) #タグaの最初の要素を取り出す
url = url.links #取り出した要素内のURLを取得
url = list(url) #list型に変換
title = element.find('span',first=True) #タグspanの最初の要素を取り出す
print(title.text) #テキストにして表示
print(url[0]) #list内は1つしか存在しないのでインデクスを0で指定して表示このプログラムについて詳しく説明していく。
一行目でelementsにclassが”yuRUbf”の要素をlist型で入れます。この要素をfor文で一つずつとりだし、その要素に対して検索をかけていく。
URLは1つ目の<a>にあるのでelementから<a>の要素の1つ目を取り出し、linksでその要素内のURLを取り出している。linksはset型で返却されるため、list型に直している。
タイトルは1つ目の<span>にあるのでURLと同様にして要素を取り出している。
よって結果は以下のようになった。
https://www.python.jp/
Python - Wikipedia - ウィキペディア
https://ja.wikipedia.org/wiki/Python
Welcome to Python.org
https://www.python.org/
Pythonってどんな言語なの?:Python入門(1/2 ページ) - @IT
https://www.atmarkit.co.jp/ait/articles/1904/02/news024.html
Python | プログラミングの入門なら基礎から学べるProgate …
https://prog-8.com/languages/python
Pythonの開発環境を用意しよう!(Windows …
https://prog-8.com/docs/python-env-win
Pythonってどんな言語? 特徴と歴史を『独習Python』から …
https://codezine.jp/article/detail/12457
Python入門 ~Pythonのインストール方法やPythonを使った …
https://www.javadrive.jp/python/
Python - Qiita
https://qiita.com/tags/pythonこのように1ページ目のタイトルとURLを取得することができた。
まとめ
完成したプログラムはこんな感じ。
from requests_html import HTMLSession
session = HTMLSession()
#検索に利用するサイト
url = "https://www.google.com/"
#検索するワード
word = "python"
r = session.get(url + "search?q=" + word)
r.html.render()
elements = r.html.find('.yuRUbf')
for element in elements:
url = element.find('a',first=True)
url = url.links#set型
url = list(url)
title = element.find('span',first=True)
print(title.text)
print(url[0])本記事ではrequests-htmlのみを使いwebスクレイピングする方法の一例として検索結果のタイトルとURLを取得するプログラムを作成した。スクレイピングにはHTMLの知識が多少必要となるためHTMLの勉強もしてみるともっといろいろなことができると思います。